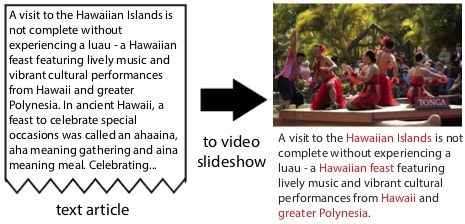
We present a system that automatically transforms text articles into audio-visual slideshows by leveraging the notion of word concreteness, which measures how strongly a word or phrase is related to some perceptible concept. In a formative study we learn that people not only prefer such audio-visual slideshows but find that the content is easier to understand compared to text articles or text articles augmented with images. We use word concreteness to select search terms and find images relevant to the text. Then, based on the distribution of concrete words and the grammatical structure of an article, we time-align selected images with audio narration obtained through text-to-speech to produce audio-visual slideshows. In a user evaluation we find that our concreteness-based algorithm selects images that are highly relevant to the text. The quality of our slideshows is comparable to slideshows produced manually using standard video editing tools, and people strongly prefer our slideshows to those generated using a simple keyword-search based approach.
|